GitHub: https://github.com/Eva-Dengyh/FastSAM-Demo
上传图片,点一下,物体被精准高亮。这不是科幻,是 Meta 开源的 SAM 2.1 + 全栈工程化的结合。
背景:什么是图像分割?
图像分割是计算机视觉的核心任务之一:给定一张图片,找出每个像素属于哪个物体。
传统方案需要大量标注数据、精调模型,门槛极高。
2023 年,Meta 发布了 Segment Anything Model(SAM),彻底改变了这一局面——它可以对任意图片、任意物体进行零样本分割,只需要用户给一个点或框作为提示。
2024 年 9 月,Meta 发布了 SAM 2.1,在更小的参数量下实现了更好的效果,同时新增视频分割能力,并以 Apache 2.0 协议完全开源。
为什么选 SAM 2,而不是 SAM 3?
Meta 的 SAM 系列目前有三代,选型时我逐一对比了一遍:
| 版本 | 发布时间 | 视频分割 | 模型大小 | 是否需要申请 |
|---|---|---|---|---|
| SAM 1 | 2023.4 | ✗ | 86M ~ 641M | 无需申请 |
| SAM 2 / 2.1 | 2024.7 / 2024.9 | ✓ | 39M ~ 224M | 无需申请 |
| SAM 3 | 2025.11 | ✓ | 未公开 | 需要申请 |
SAM 3 为什么没选?
SAM 3 于 2025 年 11 月发布,但获取权重需要在 Hugging Face 申请访问权限,审批通过后才能下载。除此之外,SAM 3 强制要求 CUDA GPU(PyTorch 2.7+、CUDA 12.6+),且许可证改为 SAM License(非 Apache 2.0),限制更多。对于想快速跑通 Demo、CPU 本地调试的场景来说,门槛太高了。
SAM 1 为什么没选?
SAM 1 不支持视频分割,且最小模型也有 86M,精度和速度均不如 SAM 2.1 的同尺寸版本。
最终选 SAM 2.1 的理由:
- 最新正式开放版本,权重直接
wget下载,零申请门槛 - 4 种尺寸(39M ~ 224M),tiny 版本 CPU 也能跑
- 图片和视频分割统一架构,扩展性好
- Apache 2.0 完全开源,商用友好

项目:FastSAM-Demo
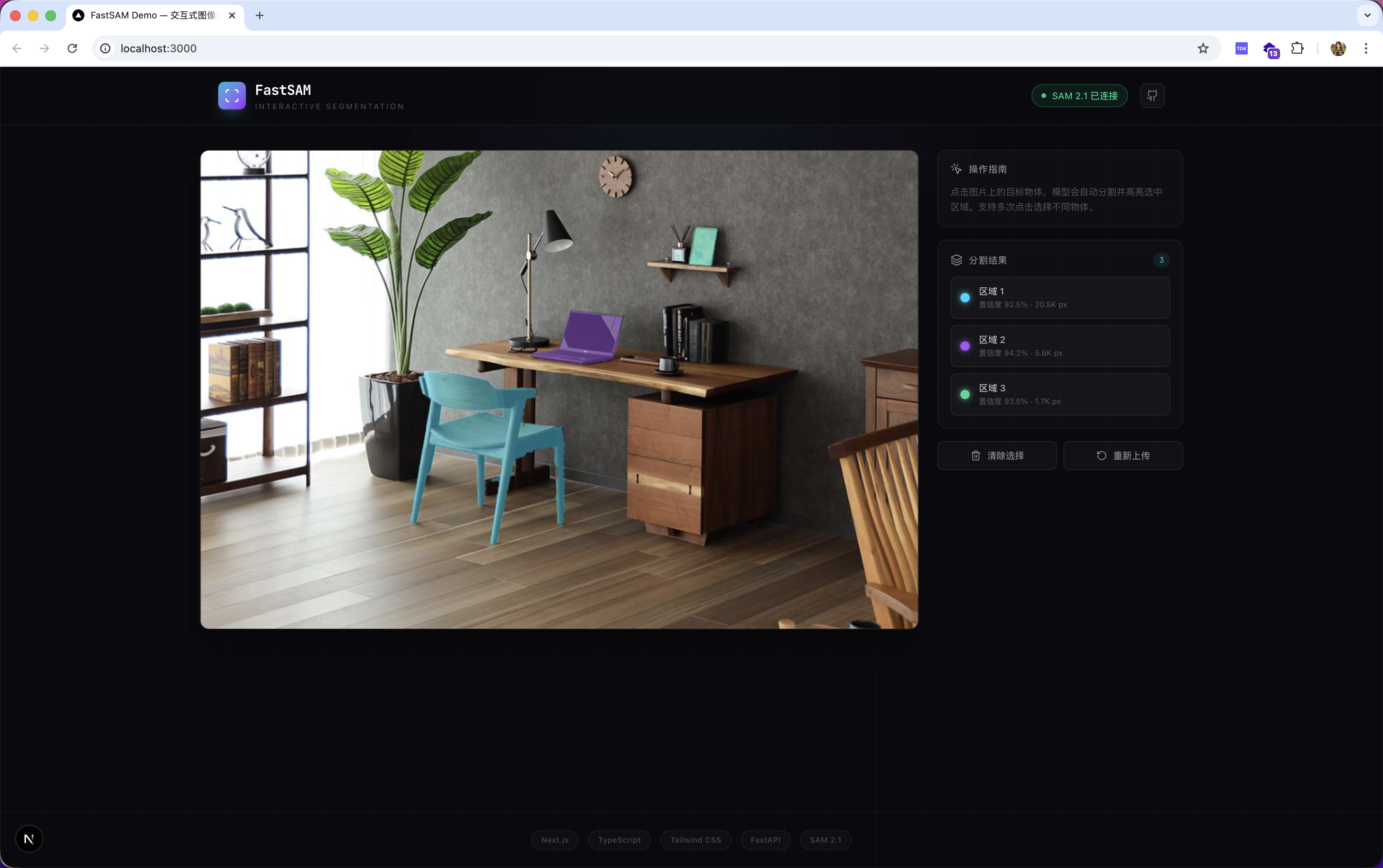
FastSAM-Demo 是一个基于 SAM 2.1 的交互式图像分割 Web 应用。
核心交互极简:上传图片 → 点击物体 → 实时高亮分割结果。
核心特性
| 特性 | 说明 |
|---|---|
| 点击即分割 | 毫秒级响应,无需等待 |
| 多模型选择 | tiny(39M) / small(46M) / base+(81M) / large(224M) |
| CPU 可跑 | tiny 模型不需要 GPU,本地 Demo 友好 |
| 多物体标注 | 不同颜色标注多个分割区域 |
| 数据高效 | RLE 压缩传输,mask 数据压缩率 > 98% |
| 无需申请 | 模型权重直接下载,Apache 2.0 开源 |
技术栈
后端:FastAPI + SAM 2.1(Python / uv)
前端:Next.js 15 + TypeScript + Tailwind CSS v4 + Framer Motion
系统架构
整体分为两层:前端负责交互与渲染,后端负责模型推理。
Browser (Next.js + TypeScript)
│
│ 用户点击图片 (x, y)
│
▼
useSegmentation Hook
│ POST /api/segment
▼
FastAPI Server
│
├── Image Cache(复用 embedding,避免重复编码)
│
└── SAM 2.1 ImagePredictor
├── set_image() ← 上传时预计算,耗时一次
└── predict() ← 每次点击调用,毫秒级返回
关键设计:Embedding 缓存
SAM 2.1 的推理分两步,耗时差距悬殊:
| 阶段 | 操作 | 耗时 |
|---|---|---|
| Image Encoder | set_image() 预计算图像特征 |
0.1s ~ 10s |
| Mask Decoder | predict() 根据点生成 mask |
10ms ~ 100ms |
关键优化:上传图片时一次性计算 embedding 并缓存,后续每次点击只跑轻量的 Mask Decoder。这是交互"毫秒级响应"的核心原因。
数据流全貌
1. 用户上传图片
→ POST /api/upload
→ 后端 set_image(),embedding 缓存到内存
→ 返回 image_id
2. 用户点击图片 (x, y)
→ 前端坐标映射(Canvas 坐标 → 原图坐标)
→ POST /api/segment { image_id, x, y }
→ 后端复用缓存 embedding,调用 predict()
→ SAM 2.1 输出 masks + scores
→ RLE 压缩后返回前端
→ 前端 Canvas 解码渲染,半透明高亮叠加原图
3. 继续点击 → 重复步骤 2,多 mask 叠加显示
SAM 2.1 核心原理
架构
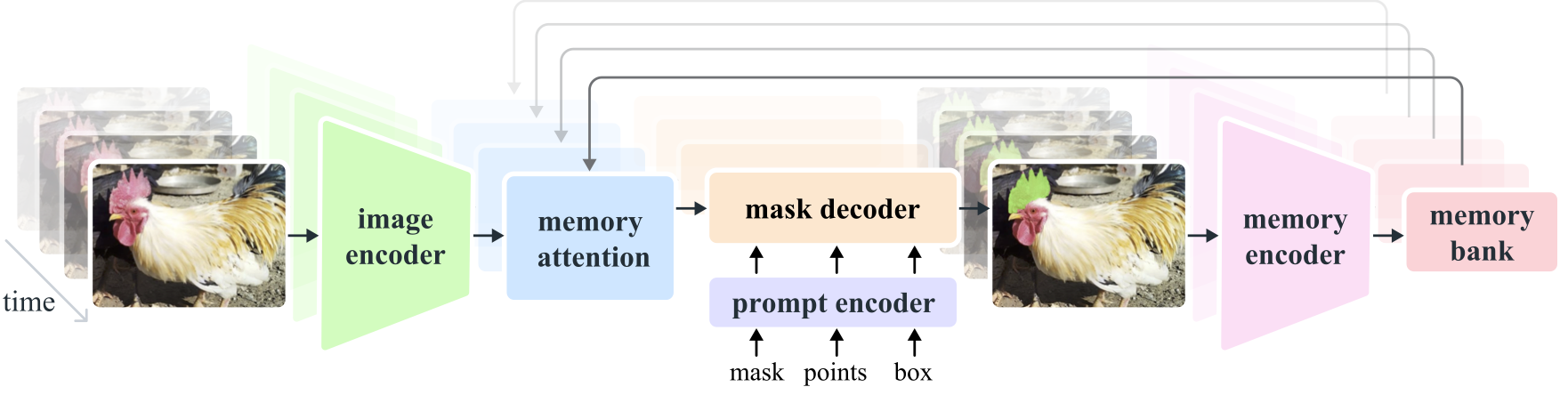
SAM 2.1 由三个核心模块组成:
图片/视频帧
│
▼
Hiera Encoder(图像编码器)
│ image embedding
▼
Mask Decoder ← Prompt Encoder(接收点/框/mask 提示)
│
▼
masks + scores + logits
- Hiera Encoder:比 SAM 1 的 ViT 更高效的层次化视觉编码器,参数量大幅缩减
- Prompt Encoder:将点击坐标、框选区域等提示信息编码
- Mask Decoder:融合图像特征和提示信息,输出分割掩码
- Memory Attention:视频模式下跨帧传递分割信息(本项目图片模式未使用)
模型尺寸对比
| 模型 | 参数量 | 推理速度(A100) | 精度(SA-V J&F) |
|---|---|---|---|
| tiny | 38.9M | 91.2 FPS | 76.5 |
| small | 46M | 84.8 FPS | 76.6 |
| base+ | 80.8M | 64.1 FPS | 78.2 |
| large | 224.4M | 39.5 FPS | 79.5 |
CPU 本地 Demo 推荐 tiny,速度与体验均衡。
前端工程化
前端采用 Next.js 15(App Router)+ TypeScript 的现代化方案,分层清晰:
types/ TypeScript 类型定义(与后端 Pydantic Schema 对齐)
lib/ API 封装 + mask RLE 解码 + Canvas 渲染工具
hooks/ useSegmentation(业务逻辑聚合)
components/ ImageUploader / SegmentCanvas / ControlPanel(纯 UI)
app/ Next.js 页面入口
核心原则:组件只管 UI,业务逻辑收归 Hook。
Next.js rewrites 代理后端 API,彻底解决 CORS 问题,前端代码无需关心后端地址。
快速上手
# 克隆项目
git clone https://github.com/Eva-Dengyh/FastSAM-Demo.git
cd FastSAM-Demo
# 一键启动(自动安装依赖 + 下载模型 + 启动前后端)
./start.sh
启动后访问:
- 前端:http://localhost:3000
- 后端 API 文档:http://localhost:8000/docs
不想一键启动?手动步骤也很简单:
# 后端
cd backend && uv sync
mkdir -p checkpoints
wget -O checkpoints/sam2.1_hiera_tiny.pt \
https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_tiny.pt
uv run uvicorn app.main:app --host 0.0.0.0 --port 8000
# 前端(新终端)
cd frontend && npm install && npm run dev
写在最后
这个项目的核心价值在于把 AI 模型 + 全栈工程实践 结合在一起:
- SAM 2.1 提供了世界级的分割能力,且完全开源免费
- FastAPI + Next.js 的全栈方案展示了清晰的工程化思路
- Embedding 缓存、RLE 压缩等细节体现了对性能的关注
如果你对 AI + Web 全栈开发感兴趣,这个项目是一个很好的起点。代码完全开源,欢迎 Star、Fork 和提 Issue。
GitHub: https://github.com/Eva-Dengyh/FastSAM-Demo